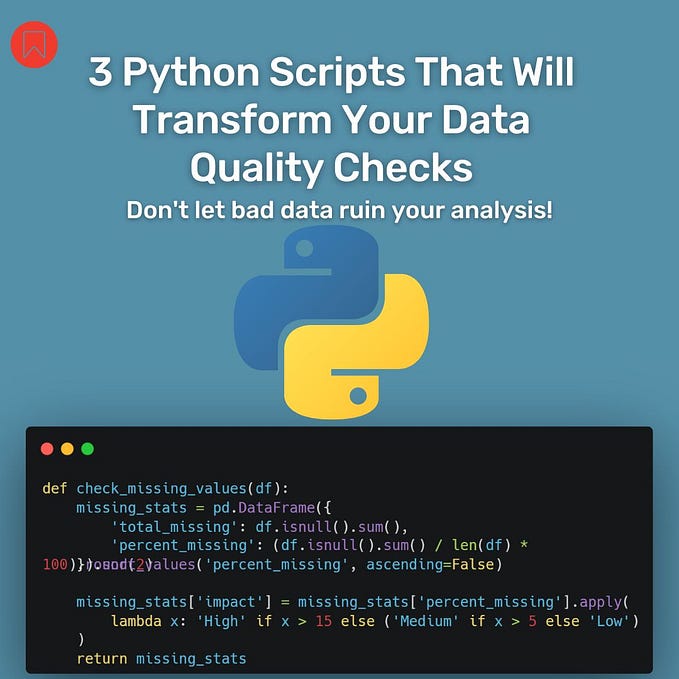
Automating Data Cleaning With Python (36/100 Days of Python)

Data cleaning is a crucial step in any data analysis project. It involves removing irrelevant, inconsistent, or incorrect data in order to prepare it for analysis. Automating the process of data cleaning with Python can save a lot of time and effort, especially for large datasets. In this tutorial, we’ll discuss how to automate data cleaning using only Python built-in functions (no additional libraries are necessary).
Scenarios Where Data Cleaning Can be Necessary
There are a few real-world scenarios where data cleaning is necessary:
- Marketing Data: In the marketing industry, data collected from various sources such as surveys, online forms, and social media platforms need to be cleaned before analysis. This data often contains inconsistent or irrelevant information, such as incorrect spelling or duplicate entries, which can skew the results of the analysis.
- Healthcare Data: In the healthcare industry, data collected from patients, medical records, and research studies needs to be cleaned in order to ensure accurate analysis and decision-making. Missing or incorrect information, such as incorrect patient ages or inconsistent data formats, can greatly affect the results of the analysis.
- Financial Data: In the financial industry, data collected from various sources such as stock market data, financial reports, and bank transactions needs to be cleaned before analysis. This data often contains incorrect or missing information, such as incorrect dates or missing values, which can skew the results of the analysis.
- Retail Data: In the retail industry, data collected from sales transactions and customer information needs to be cleaned before analysis. This data often contains irrelevant or inconsistent information, such as incorrect product names or inconsistent customer addresses, which can affect the results of the analysis.
- Weather Data: In the meteorological industry, data collected from various sources such as weather stations and satellite data needs to be cleaned before analysis. This data often contains missing or incorrect information, such as incorrect dates or missing temperature readings, which can affect the results of the analysis.
These are just a few examples, but data cleaning is necessary for many other industries as well. The goal is always to ensure that the data is accurate, consistent, and relevant before it is analyzed. So, let’s dive in and see how this can be done in Python.
Loading Data into Python
The first step in automating data cleaning is to import the data into Python. In this tutorial, we’ll be using a CSV (Comma-Separated Values) file as an example, but you can also use other file formats such as Excel, JSON, or SQL. An example csv file might look something like this:
Name,Age,Gender,City,Occupation
John Doe,32,Male,New York,Engineer
Jane Doe,28,Female,Los Angeles,Doctor
Michael Smith,40,Male,Chicago,Teacher
Emily Brown,35,Female,Houston,NurseTo import a CSV file in Python, we’ll use the built-in csv module. The following code will read the data from the file and store it in a list of dictionaries:
import csv
with open('data.csv', 'r') as f:
reader = csv.DictReader(f)
data = list(reader)After reading the file, data will contain a list of entries, where each entry is a dictionary containing the values. The data from the previous example might look something like this:
data = [
{'Name': 'John Doe', 'Age': '32', 'Gender': 'Male', 'City': 'New York', 'Occupation': 'Engineer'},
{'Name': 'Jane Doe', 'Age': '28', 'Gender': 'Female', 'City': 'Los Angeles', 'Occupation': 'Doctor'},
{'Name': 'Michael Smith', 'Age': '40', 'Gender': 'Male', 'City': 'Chicago', 'Occupation': 'Teacher'},
{'Name': 'Emily Brown', 'Age': '35', 'Gender': 'Female', 'City': 'Houston', 'Occupation': 'Nurse'},
]Handling Missing Values
Missing values can cause problems during data analysis, so it’s important to handle them appropriately. There are several ways to handle missing values in Python, including replacing them with a default value, dropping the missing values, or imputing the missing values with statistical methods.
In this tutorial, we’ll replace the missing values with the mean of the column. The following code will replace all missing values in the “Age” column with the mean age of the data:
def replace_missing_values(data, column, value):
for row in data:
if row[column] == '':
row[column] = value
return data
present_ages = [int(row['Age']) for row in data if row['Age'] != '']
mean_age = sum(present_ages) / len(present_ages)
data = replace_missing_values(data, 'Age', mean_age)Handling Duplicate Values
Duplicate values can also cause problems during data analysis, so it’s important to identify and remove them. The following code will remove all duplicates in the data based on the values in the “Name” column:
def remove_duplicates(data, column):
seen = set()
new_data = []
for row in data:
if row[column] not in seen:
new_data.append(row)
seen.add(row[column])
return new_data
data = remove_duplicates(data, 'Name')Saving the Cleaned Data
Once you have finished cleaning the data, you can save it back to a file. The following code will write the cleaned data back to a CSV file:
with open('cleaned.csv', 'w', newline='') as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
writer.writeheader()
for row in data:
writer.writerow(row)This process can be repeated for any type of data — it can be textual data, it can be a list of URLs that need to be filtered, it can be some information about birth dates of patients saved in a json file, or a csv file as described above.
Data cleaning is essential in many industries, such as marketing, healthcare, finance, retail, meteorology, and many more, as it ensures that the collected data is accurate, consistent, and relevant before analysis. By handling missing values, duplicates, and inconsistent data, one can prepare the data for analysis and ensure that the results of the analysis are not skewed by errors and inconsistencies.
What’s next?
- If you found this story valuable, please consider clapping multiple times (this really helps a lot!)
- Hands-on Practice: Free Python Course
- Full series: 100 Days of Python
- Previous topic: With Statement
- Next topic: Positional-only and Keyword-only Arguments